Le fichier robots.txt est un fichier texte placé sur votre serveur web qui indique aux robots Web (tels que Googlebot) les fichiers de votre site auxquels ils peuvent (ou non) accéder.
Ne vous y trompez pas, malgré sa petite taille, c'est une pièce maîtresse pour l'optimisation technique de votre site web. Il vous faut donc apprendre à le connaitre et à le maîtriser pour favoriser l'exploration et l'indexation de votre contenu par les robots des moteurs de recherche.
Le fichier robots.txt
Pourquoi est-ce important de connaitre le fichier robots.txt ?
Plusieurs raisons expliquent pourquoi vous devez absolument maîtriser ce fichier :
- L'absence ou une mauvaise utilisation du fichier robots.txt peut nuire à votre classement,
- Le fichier robots.txt contrôle la manière dont les robots des moteurs de recherche voient et interagissent avec vos pages,
- Ce fichier est mentionné dans les consignes d'ordre général de Google,
- Ce fichier, et les bots qui interagissent avec, sont des éléments fondamentaux de la façon dont les moteurs de recherche travaillent.
Puisque votre site est propulsé par Joomla, celui-ci est livré nativement avec un fichier robots.txt conforme aux recommandations des moteurs de recherche. Ce fichier est tout sauf anodin et une (très) bonne compréhension de son utilisation est donc indispensable pour contrôler ce que les robots peuvent voir de votre site. C'est ce que nous allons voir maintenant.
Comme utiliser le fichier robots.txt ?
La première chose qu'un robot comme Googlebot regarde quand il arrive sur un site web, c'est le contenu du fichier robots.txt (s'il est présent, bien sur).
Il procède de la sorte parce qu'il veut d'abord savoir si il a l'autorisation d'accéder à vos pages, aux fichiers de votre site ou à un de ses dossiers. Si le fichier robots.txt bloque l'accès à un fichier, le robot du moteur de recherche passe au fichier / dossier suivant et ainsi de suite.
Maintenant que nous savons comment procédent les robots, entrons dans le vif du sujet.
Pour comprendre comment fonctionne le fichier robots.txt, voyons ce qu'il contient.
Première bonne nouvelle, il est facile à trouver car ce fichier est toujours placé à la racine de votre site web :
Seconde bonne nouvelle, ce type de fichier s'ouvre et se modifie avec le bloc notes de votre ordinateur (ou TextEdit si vous utilisez un Mac).
Regardons ce qu'il contient :
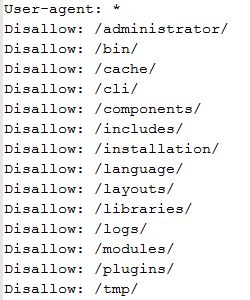
Ce que vous voyez ce sont les instructions données aux robots. Dans l'exemple ci-dessus, l'accès aux dossiers indiqués est refusé aux robots.
Détaillons maintenant quelques exemples pour aborder la logique de fonctionnement :
Accès complet
User-agent: *
Disallow:
Bloque tous les accès
User-agent: *
Disallow: /
Bloque un dossier
User-agent: *
Disallow: /dossier/
Bloque un fichier
User-agent: *
Disallow: /page-web.html
Dans ces quelques exemples, le nom de l'user-agent est remplacé par un astérisque. Cela indique que l'instruction s'applique à tous les robots.
Il est naturellement possible de donner une instruction précise à un seul user-agent :
User-agent: Googlebot
Allow: /
Reprenons l'exemple du fichier robots.txt natif de Joomla.
Certains dossiers ne sont pas cités (par exemple, le dossier "images"). En effet, par définition, tout ce qui n'est pas bloqué est autorisé.
Mais pour s'assurer que Googlebot va bien indexer les images de votre site, nous allons lui indiquer que la voie est libre :
Allow: /images/
Nous pouvons également décider de bloquer l'accès à un dossier complet à tous les robots mais autoriser Googlebot a indexer un fichier spécifique dans ce même dossier :
User-agent: *
Disallow: /images
Allow: /images/ma-photo.jpg
On peut tout aussi bien donner une instruction précise à l'user-agent Googlebot-images :
# Autoriser Google Image
User-agent: Googlebot-Image
Allow: /images
Explications et détails
Concrétement, toutes les instructions du fichier robots.txt peuvent se résumer par l'un de ces trois scénariis :
- Autorisation : Tout le contenu peut être analysé,
- Refus : Aucun contenu peut être analysé,
- Autorisation conditionnelle : Les directives contenues dans le fichier robots.txt déterminent la capacité d'analyser certains contenus.
Voyons maintenant cela en détail :
Autorisation : Tout le contenu peut être analysé
Le plkus souvent, les propriétaires de site veulent que les robots visitent la totalité de leur site web. Si tel est votre cas et que vous voulez que les robots indexent toutes les parties de votre site, il existe trois options pour leur indiquer qu'ils sont les bienvenus.
- Ne pas avoir de fichier robots.txt
Si vous n'avez pas de fichier robots.txt sur votre site (ou que vous l'avez supprimé), les robots pourront alors visiter (crawler) toutes les pages Web et tout le contenu de votre site parce qu'ils sont programmés pour ça dans cette configuration.
- Avoir un fichier robots.txt vide
Supprimez tout le contenu du fichier robots.txt natif de Joomla présent à la racine de votre site. En faisant cela, les robots pourront visiter (crawler) toutes les pages Web et tout le contenu de votre site parce qu'ils sont programmés pour ça dans cette situation.
- Utiliser la syntaxe adéquate
Pour permettre à tous les robots de visiter (crawler) toutes les pages Web et tous vos contenus, utilisez de préférence la syntaxe suivante dans votre fichier robots.txt :
User-agent: *
Disallow:Lorsque le robot arrive sur votre site, il recherche d'abord la présence du fichier robots.txt. Si celui-ci est présent, il l'ouvre pour accéder à son contenu. Il lit alors la première ligne et éxécute l'instruction présente. Ici, le robot comprend qu'il peut tout visiter.
Refus : Aucun contenu peut être analysé,
Attention, vous allez indiquer aux robots qu'ils ne peuvent pas accéder aux pages et aux contenus de votre site.
Pour bloquer l'accès à tous les robots, ajoutez uniquement et seulement cette instruction dans votre fichier robots.txt:
User-agent: *
Disallow: /
Pourquoi vouloir faire ça ?
En effet, cela peut sembler paradoxal d'empêcher les robots d'accéder au contenu d'un site alors que nous parlons de référencement. Pourtant, il existe un cas qui justifie pleinement l'emploi de cette instruction.
Lors de la phase de développement d'un site, il n'est pas nécessaire que les robots viennent indexer les données d'exemple (textes et images) qui ont pu être installées avec Joomla. Surtout qu'une fois indexées, celles-ci seront considérées comme faisant partie intégrante du site.
Vous pouvez donc bloquer l'accès aux robots durant la phase de développement et vous ajusterez le contenu de votre fichier robots.txt selon vos besoins une fois le site terminé et prêt à être mis en production.
Utilisation avancée du fichier robots.txt
Maintenant que nous avons vu comment dialoguer avec les robots, nous allons voir comment tirer partie de ce fichier.
Si nous pouvons bloquer / autoriser les robots à accéder à notre site, nous allons voir qu'il est possible de s'en servir pour améliorer la sécurité du site ou encore, comment éviter le contenu dupliqué (chose dont a horreur l'ami Google).
Bloquer l'indexation de fichiers sensibles :
User-agent: *
Disallow: /*.php$
Disallow: /*.inc$
Disallow: /*.gz$
Disallow: /*.pdf$
Désindéxer les URLs ayant certains paramètres pour éviter le contenu dupliqué
Disallow: /*?*
Disallow: /*?
Disallow: /*&
Indiquer l'adresse URL de votre fichier Sitemap
Sitemap: https://www.nom-de-domaine.fr/sitemap.xml
Recommandations sur l'utilisation du fichier robots.txt
- Si vous utilisez le fichier robots.txt, assurez-vous impérativement que les instructions qu'il contient soient valides,
- La moindre erreur peut bloquer l'accès à des pages qui devraient être indexées par les robots,
- Assurez-vous de ne bloquer aucune ressources utiles à la compréhension du contenu de votre site par Google.
Pour nous aider à comprendre le contenu de votre site de manière exhaustive, autorisez l'exploration de tous les éléments de votre site ayant un impact important sur l'affichage de la page, tels que les fichiers CSS et JavaScript qui influent sur l'interprétation des pages. Notre système d'indexation affiche les pages Web telles qu'elles sont présentées aux internautes, y compris pour les fichiers image, CSS et JavaScript.
Source : Consignes aux webmasters - Google centre d'aide Search Console
Liste des user-agent
Le web est un monde merveilleux. Je vous ai trouvé une très riche base de données sur le site https://sql.sh contenant un nombre très important d'user-agent. Cette base de données est disponible sous plusieurs formats :
Conclusion
Vous connaissez maintenant le mode de fonctionnement des moteurs de recherche et comment "dialoguer" avec leurs robots. Avouez que ce n'est pas très compliqué ;)
Ces étapes sont néanmoins essentielles à la bonne compréhension de l'optimisation technique d'un site web pour son référencement.