The statement about the efficiency of SEO tools in driving more organic traffic to your site isn’t under debate — it is an already proven reality. However, as with other parameters, defining the quality of your online presence is important to ensure your domain’s health and avoid novice mistakes. Given that over 65% of all internet-based interactions start with a simple search engine query, your task is to ensure a top-notch keyword profile and track your position in the related SERPs.
The aforementioned is the rule of thumb to hack the popularity of any website. Nevertheless, there is always a “but.” One of the reasons well-ranged keywords, backlinks from authority donor pages, and so on don’t work efficiently is that you overlook the quality of your content and miss duplicated data on the web. Google doesn’t tolerate such alerts from crawling bots. So today’s mission is clear — to learn how to detect and eliminate these deficiencies. Onwards!
What You Should Know About Duplicate Content
The term itself is self-explanatory and refers to the data that occurs twice or more on the internet. However, there is a nuance — it pays special attention to word-for-word copies of texts or their abstracts on different resources. It also describes the near-the-same way of information representation, which obviously excludes the efficiency of slightly rewritten content.
Whether there is a problem of complete or particular content duplication, there are no “legal” consequences for it. Nevertheless, it doesn’t mean you are protected from any challenges and can forget to avoid this issue. It has a huge impact on your site’s ranking. The key reason is that you confuse search engine crawling and indexing mechanisms, preventing it from precisely evaluating your effort.
In turn, all the pages with duplicate content, whether they belong to one or a couple of hosts, aren’t included in the ranking parameters. Google marks appreciably similar content parts as improper, except for a few possible versions based on particular synonyms—that scenario you would prefer avoiding, especially for crucial keywords.
Ranking Lower vs. Ranking Higher: Is There a Crucial Difference?
Let’s check what statistical analytics say about this issue. Since around 93% of search traffic is generated by search engines, ranking lower for your target keywords means exposing yourself to blow. With the help of professional tools like Serpstat Rank Tracker, specialists can monitor their site’s performance and rankings in SERPs.
Duplicate content is a highway to altering the page’s relevancy when you either lose to the competitor with a better double or drag both of you to the bottom of ratings. In turn, promoting the wrong pages in SERPs won’t satisfy your SEO and business goals:
- You might lose the chance to reach out to the target audience, who specifically prefers a particular selection of keywords. Duplicate content may ruin your local SEO effort here.
- On the other hand, poor indexing will reduce your website visibility, negatively influencing customer awareness of your products and services.
Main Duplicate Content Causes
Neither the volume nor age of the domain prevents aspects from duplicate content appearance — this issue concerns and affects everyone. It won’t stop the flow of organic traffic since users can still access your pages. However, their ability to do so can be significantly limited because of search engine robots.
Before focusing on alternative strategies to boost your rating in SERPs and professional SEO tools, you must get acquainted with your enemy in more detail. Duplicate content is trickier than it might seem at first.
Duplicate Referral Links
That’s where attention to detail matters a lot. The cases when developers regrettably neglect their duties to adjust the performance of links that begin with “?ref=...” are frequent. Once that happens, viewers aren’t automatically redirected to the target site. Such links harm your website’s trustworthiness in the eyes of Google and reduce your e-commerce potential.
To Slash or Not to Slash
Another frequent reason for this issue is when a domain has two different URLs with the only distinctive element — the presence or absence of a slash. Please ensure your URLs don’t look like in the examples below:
- mybookrealm.com/sales vs. mybookrealm.com/sales/;
- blog.translates.com/IT vs. blog.translates.com/IT/.
Sorting & Filters
These factors “complement” dynamic URL-generated results with automated and unnecessary pages, which are pointless for indexing and your SEO strategy. In turn, the total size of the website grows. In turn, the crawling budget isn’t applied efficiently. This term represents the total number of pages a search engine robot can view in one visit to the target platform.
With or Without WWW
It is a similar issue to slashes in URLs. Suppose there are platforms with the same content aside from a www use. Duplicate content flourishes if you permit access to your domain via a URL with HTTPS or HTTP.
Suitable for Printing
SEO experts have to be careful about employing the power of CMS systems. Search engines may identify print-friendly pages as duplicates. Additionally, this issue occurs if you don’t explicitly “tell” the target page to restrict search engine crawlers on special-for-printing-purposes areas of your site.
Comment Pagination
Despite how appealing the idea of avoiding scroll navigation with comment pagination seems, it leads to a significant misunderstanding with search engines. Yahoo and Google may question the worth of paginated comments, especially if the process needs to be executed correctly.
Content Syndication and Scrapers
In the modern era of globalization, you don’t require a permit to employ third-party content and vice versa, especially regarding white hat link-building and guest blogging. However, if a host fails to provide a proper anchor text or quote to the original content source, expect trouble.
This issue typically arises when your syndicated content begins to gain popularity. Although you certainly entice more users to check your site and enhance your site’s reach, you might lose control over its distribution and cause duplicates.
Tracking Settings
Experts can apply specific sorting and tracking parameters to collect and monitor link visits. It can simplify the challenge a lot. However, adding such trackers to your pages’ URLs has a negative impact on increasing the amount of duplicates on your site.
There is a difference between partner and paid search tracking links:
- The first category implies standard HTML links, easily accessible for search engine detection and analysis.
- The second category is typically no-followed or JavaScript-generated and doesn’t cause any disruption with crawling processes.
Session IDs
The brief account of a visitor's actions while checking your site specifies their session — its duration, the number and quality of clicks, etc. Every visit of this kind gets its number. In certain systems, where such IDs are attached to the pages’ URLs, issues of duplicates arise momentarily.
Generating Identifies out of Article IDs
CMSs are gaining momentum for several reasons. They are more than just tools for creating and sharing content. On the other hand, they enable SEO specialists to adjust the site’s pages and build a clear web layout or SEO-friendly URLs and anchors. Still, beginner mistakes can occur when the CMS’s database lets a post happen via different links. Considering that these are unique identifiers for search engines to index content online, the core of the problem is clear.
How to Cope with Duplicate Content Challenges
Since you have gotten acquainted with the most typical types and causes of duplicates online, now is the right moment to discover functional recovery methods with a proven effect. Let’s immediately roll straight into this guide's most intriguing section. Keep on reading for ready-made solutions for your duplicate-content anxiety!
Meta Robots Noindex
This method is popular and aimed at preventing search engine bots from evaluating duplicate websites and pages. When constructing a URL for such content, don’t forget to include the related tag in the link design. Please ensure your pages are easily accessible since robots must visit them to find corresponding noindex rules. In the opposite case, the bot's inability to handle this code would prevent it from recognizing the hidden noindex directive.
Implement Rel="canonical"
To avoid competing with the original content source, interested parties can add a "rel=canonical" tag. It becomes an extra attribute in the replica page's HTML head. Still, it is important to highlight the original page’s URL when inserting your code. This way, you ensure crawlers can appropriately determine the rank of two pages with similar content. Remember to use quotation markets since they are on the list of code requirements.
There are a couple of methods to implement this tag on your site:
- You can edit the header coding of your domain individually.
- You can address this problem via a Joomla extension.
- SEO specialists adjust this parameter on their own to eliminate the risk of failure.
To get acquainted with this tag and its SEO aspects, this guide is a marvelous source of information, boosting your awareness: https://serpstat.com/blog/how-to-use-relcanonical-tag-for-seo/.
The Show of 301 Redirects
Regarded as the primary technique for getting rid of exact data copies on sites, it allows you to adjust an automatic redirect from point A to point B. In this case, you inform bots that another URL page should be estimated and crawled. These redirects will prove their efficiency for print-friendly pages and tracking page codes.
Content Paraphrasing
In this case, you create new content with similar senses and ideas. Since the representation format changes, it isn’t estimated as plagiarized or duplicated information. To ensure this solution works fully, don’t forget to stick to the appropriate keyword paradigm to hit the right target audience and market.
If you don’t want to hire professional writers, testing the performance of AI tools is possible. They will come in handy to reorganize, rephrase, and translate your pages at full tilt. Don’t forget to check and edit it to ensure the value of the fixed version. If you hesitate about your skills to complete the task, Serpstat Blog comes to the rescue and helps you work with AI-empowered technologies to improve your content in diverse formats and styles.
Plagiarism Checks
Such tools make finding copies of your content easier, especially in non-intentional plagiarism cases. With Serpstat, you can improve your SEO strategy and validate your content simultaneously — it has an in-built plagiarism detector. If the issue is spotted, there are two common ways out:
- Experts can add quotes and use other techniques to ensure their content isn’t indexed as duplicates.
- On the contrary, instead of adding hyperlinks and working on your backlinks profile, you can paraphrase the vulnerable abstract or text to ensure its uniqueness and quality.
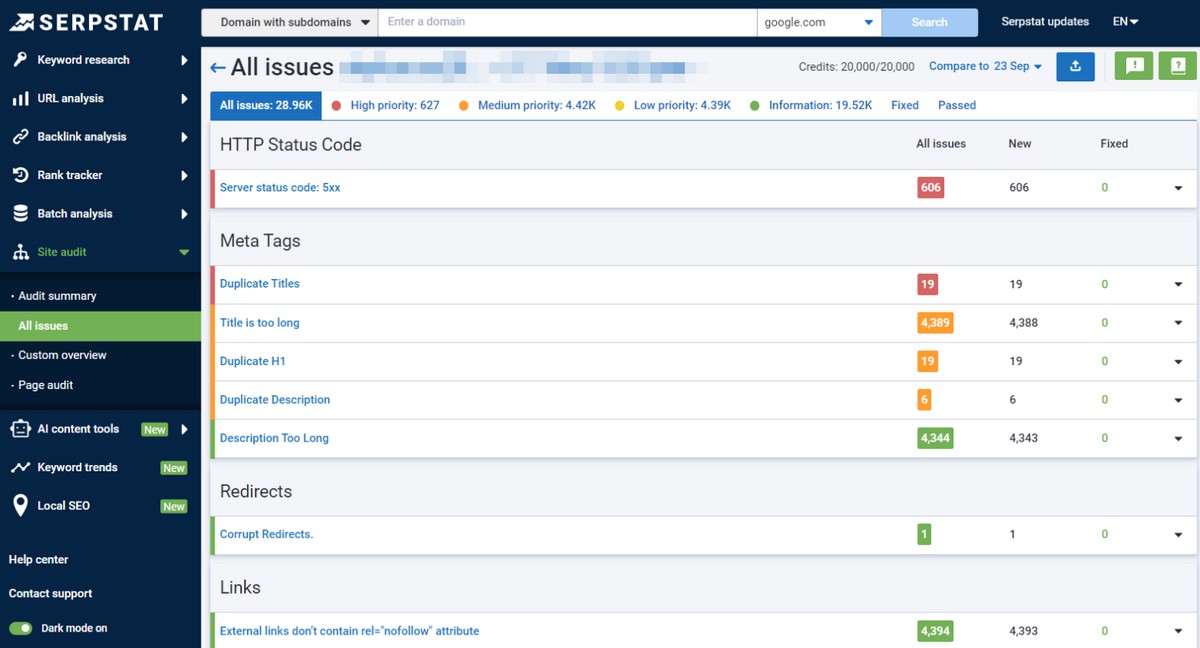
Site Audit Tools
Employing SEO software to handle duplicate content is the most professional approach on the list. With high-end tools like Serpstat Site Audit, you kill two birds with one stone — discover risky zones and find proper solutions to those new issues.
To start, enter your domain name, adjust the session’s parameters, and initiate the process. The list includes the scanning technique, the quantity of pages to analyze, the procedure’s speed, delivery results, and so on. SEO experts will obtain the overall health score of the target page or domain and clearly see what duplicate issues are, as well as their intensity and location.
Boost Your SEO Strategy with CRM Tools
So-called customer relationship management systems are designed to collect client interactions with your service and provide centralized access to their tracking and analytics. This way, you can enhance customer satisfaction and delivery experiences, benefiting regular and prospective visitors of your platform. At the same time, CRM software can assist in organizing your SEO efforts, particularly when locating and removing duplicate content.
Let’s check a few ways in which CRM tools will come in handy for this purpose:
- Contact content syndication platforms — with the help of CRM, you won’t face any difficulty reaching out to so-called content syndicators. This process is streamlined by your prompt and reliable access to this data, minimizing the risk of overlooking crucial details and contacts. Considering that CRM solutions can help shape and personalize your link-building and SEO parameters, it is a win-win scenario.
- Opportunities for inserting links — a high-end CRM solution is a great way to implement valuable data from third parties to your blog or other on-site pages without duplicate content and other issues. That reduces the overall stress and pressure, letting you skip writing articles from scratch every time you post something. CRM software automates the link-building process and assists in monitoring the way the target audience’s perception.
- Guest blogging — without a doubt, it is one of the easiest and most effective methods to generate and elevate your backlink profile. If you don’t want to lose track of prospective third parties to cooperate with, professional CRM solutions will help you fulfill guest blogging projects. It is a functional way to distinguish this effort from content syndication and prospective traffic cannibalism.
Final Thoughts
If you don’t want to face a sharp decline in your site’s ranks and a loss of organic traffic, taking care of duplicate content in advance is an excellent precautionary measure. This way, you will ensure your pages deliver only relevant and valid information while satisfying the needs of potential viewers and Google’s guidelines. Don’t hesitate to follow the recommendations described in this guide to guarantee your site’s steady performance.
This guest post have been gifted to Serpstat as a support to Ukraine people, economy and companies.
Цю гостьову публікацію було подаровано Serpstat, щоб висловити мою підтримку людям, економіці та компаніям України
The statement about the efficiency of SEO tools in driving more organic traffic to your site isn’t under debate — it is an already proven reality. However, as with other parameters, defining the quality of your online presence is important to ensure your domain’s health and avoid novice mistakes. Given that over 65% of all internet-based interactions start with a simple search engine query, your task is to ensure a top-notch keyword profile and track your position in the related SERPs.
The aforementioned is the rule of thumb to hack the popularity of any website. Nevertheless, there is always a “but.” One of the reasons well-ranged keywords, backlinks from authority donor pages, and so on don’t work efficiently is that you overlook the quality of your content and miss duplicated data on the web. Google doesn’t tolerate such alerts from crawling bots. So today’s mission is clear — to learn how to detect and eliminate these deficiencies. Onwards!
What You Should Know About Duplicate Content
The term itself is self-explanatory and refers to the data that occurs twice or more on the internet. However, there is a nuance — it pays special attention to word-for-word copies of texts or their abstracts on different resources. It also describes the near-the-same way of information representation, which obviously excludes the efficiency of slightly rewritten content.
Whether there is a problem of complete or particular content duplication, there are no “legal” consequences for it. Nevertheless, it doesn’t mean you are protected from any challenges and can forget to avoid this issue. It has a huge impact on your site’s ranking. The key reason is that you confuse search engine crawling and indexing mechanisms, preventing it from precisely evaluating your effort.
In turn, all the pages with duplicate content, whether they belong to one or a couple of hosts, aren’t included in the ranking parameters. Google marks appreciably similar content parts as improper, except for a few possible versions based on particular synonyms—that scenario you would prefer avoiding, especially for crucial keywords.
Ranking Lower vs. Ranking Higher: Is There a Crucial Difference?
Let’s check what statistical analytics say about this issue. Since around 93% of search traffic is generated by search engines, ranking lower for your target keywords means exposing yourself to blow. With the help of professional tools like Serpstat Rank Tracker, specialists can monitor their site’s performance and rankings in SERPs.
Duplicate content is a highway to altering the page’s relevancy when you either lose to the competitor with a better double or drag both of you to the bottom of ratings. In turn, promoting the wrong pages in SERPs won’t satisfy your SEO and business goals:
- You might lose the chance to reach out to the target audience, who specifically prefers a particular selection of keywords. Duplicate content may ruin your local SEO effort here.
- On the other hand, poor indexing will reduce your website visibility, negatively influencing customer awareness of your products and services.
Main Duplicate Content Causes
Neither the volume nor age of the domain prevents aspects from duplicate content appearance — this issue concerns and affects everyone. It won’t stop the flow of organic traffic since users can still access your pages. However, their ability to do so can be significantly limited because of search engine robots.
Before focusing on alternative strategies to boost your rating in SERPs and professional SEO tools, you must get acquainted with your enemy in more detail. Duplicate content is trickier than it might seem at first.
Duplicate Referral Links
That’s where attention to detail matters a lot. The cases when developers regrettably neglect their duties to adjust the performance of links that begin with “?ref=...” are frequent. Once that happens, viewers aren’t automatically redirected to the target site. Such links harm your website’s trustworthiness in the eyes of Google and reduce your e-commerce potential.
To Slash or Not to Slash
Another frequent reason for this issue is when a domain has two different URLs with the only distinctive element — the presence or absence of a slash. Please ensure your URLs don’t look like in the examples below:
- mybookrealm.com/sales vs. mybookrealm.com/sales/;
- blog.translates.com/IT vs. blog.translates.com/IT/.
Sorting & Filters
These factors “complement” dynamic URL-generated results with automated and unnecessary pages, which are pointless for indexing and your SEO strategy. In turn, the total size of the website grows. In turn, the crawling budget isn’t applied efficiently. This term represents the total number of pages a search engine robot can view in one visit to the target platform.
With or Without WWW
It is a similar issue to slashes in URLs. Suppose there are platforms with the same content aside from a www use. Duplicate content flourishes if you permit access to your domain via a URL with HTTPS or HTTP.
Suitable for Printing
SEO experts have to be careful about employing the power of CMS systems. Search engines may identify print-friendly pages as duplicates. Additionally, this issue occurs if you don’t explicitly “tell” the target page to restrict search engine crawlers on special-for-printing-purposes areas of your site.
Comment Pagination
Despite how appealing the idea of avoiding scroll navigation with comment pagination seems, it leads to a significant misunderstanding with search engines. Yahoo and Google may question the worth of paginated comments, especially if the process needs to be executed correctly.
Content Syndication and Scrapers
In the modern era of globalization, you don’t require a permit to employ third-party content and vice versa, especially regarding white hat link-building and guest blogging. However, if a host fails to provide a proper anchor text or quote to the original content source, expect trouble.
This issue typically arises when your syndicated content begins to gain popularity. Although you certainly entice more users to check your site and enhance your site’s reach, you might lose control over its distribution and cause duplicates.
Tracking Settings
Experts can apply specific sorting and tracking parameters to collect and monitor link visits. It can simplify the challenge a lot. However, adding such trackers to your pages’ URLs has a negative impact on increasing the amount of duplicates on your site.
There is a difference between partner and paid search tracking links:
- The first category implies standard HTML links, easily accessible for search engine detection and analysis.
- The second category is typically no-followed or JavaScript-generated and doesn’t cause any disruption with crawling processes.
Session IDs
The brief account of a visitor's actions while checking your site specifies their session — its duration, the number and quality of clicks, etc. Every visit of this kind gets its number. In certain systems, where such IDs are attached to the pages’ URLs, issues of duplicates arise momentarily.
Generating Identifies out of Article IDs
CMSs are gaining momentum for several reasons. They are more than just tools for creating and sharing content. On the other hand, they enable SEO specialists to adjust the site’s pages and build a clear web layout or SEO-friendly URLs and anchors. Still, beginner mistakes can occur when the CMS’s database lets a post happen via different links. Considering that these are unique identifiers for search engines to index content online, the core of the problem is clear.
How to Cope with Duplicate Content Challenges
Since you have gotten acquainted with the most typical types and causes of duplicates online, now is the right moment to discover functional recovery methods with a proven effect. Let’s immediately roll straight into this guide's most intriguing section. Keep on reading for ready-made solutions for your duplicate-content anxiety!
Meta Robots Noindex
This method is popular and aimed at preventing search engine bots from evaluating duplicate websites and pages. When constructing a URL for such content, don’t forget to include the related tag in the link design. Please ensure your pages are easily accessible since robots must visit them to find corresponding noindex rules. In the opposite case, the bot's inability to handle this code would prevent it from recognizing the hidden noindex directive.
Implement Rel="canonical"
To avoid competing with the original content source, interested parties can add a "rel=canonical" tag. It becomes an extra attribute in the replica page's HTML head. Still, it is important to highlight the original page’s URL when inserting your code. This way, you ensure crawlers can appropriately determine the rank of two pages with similar content. Remember to use quotation markets since they are on the list of code requirements.
There are a couple of methods to implement this tag on your site:
- You can edit the header coding of your domain individually.
- You can address this problem via a Joomla extension.
- SEO specialists adjust this parameter on their own to eliminate the risk of failure.
To get acquainted with this tag and its SEO aspects, this guide is a marvelous source of information, boosting your awareness: https://serpstat.com/blog/how-to-use-relcanonical-tag-for-seo/.
The Show of 301 Redirects
Regarded as the primary technique for getting rid of exact data copies on sites, it allows you to adjust an automatic redirect from point A to point B. In this case, you inform bots that another URL page should be estimated and crawled. These redirects will prove their efficiency for print-friendly pages and tracking page codes.
Content Paraphrasing
In this case, you create new content with similar senses and ideas. Since the representation format changes, it isn’t estimated as plagiarized or duplicated information. To ensure this solution works fully, don’t forget to stick to the appropriate keyword paradigm to hit the right target audience and market.
If you don’t want to hire professional writers, testing the performance of AI tools is possible. They will come in handy to reorganize, rephrase, and translate your pages at full tilt. Don’t forget to check and edit it to ensure the value of the fixed version. If you hesitate about your skills to complete the task, Serpstat Blog comes to the rescue and helps you work with AI-empowered technologies to improve your content in diverse formats and styles.
Plagiarism Checks
Such tools make finding copies of your content easier, especially in non-intentional plagiarism cases. With Serpstat, you can improve your SEO strategy and validate your content simultaneously — it has an in-built plagiarism detector. If the issue is spotted, there are two common ways out:
- Experts can add quotes and use other techniques to ensure their content isn’t indexed as duplicates.
- On the contrary, instead of adding hyperlinks and working on your backlinks profile, you can paraphrase the vulnerable abstract or text to ensure its uniqueness and quality.
Site Audit Tools
Employing SEO software to handle duplicate content is the most professional approach on the list. With high-end tools like Serpstat Site Audit, you kill two birds with one stone — discover risky zones and find proper solutions to those new issues.
To start, enter your domain name, adjust the session’s parameters, and initiate the process. The list includes the scanning technique, the quantity of pages to analyze, the procedure’s speed, delivery results, and so on. SEO experts will obtain the overall health score of the target page or domain and clearly see what duplicate issues are, as well as their intensity and location.
Boost Your SEO Strategy with CRM Tools
So-called customer relationship management systems are designed to collect client interactions with your service and provide centralized access to their tracking and analytics. This way, you can enhance customer satisfaction and delivery experiences, benefiting regular and prospective visitors of your platform. At the same time, CRM software can assist in organizing your SEO efforts, particularly when locating and removing duplicate content.
Let’s check a few ways in which CRM tools will come in handy for this purpose:
- Contact content syndication platforms — with the help of CRM, you won’t face any difficulty reaching out to so-called content syndicators. This process is streamlined by your prompt and reliable access to this data, minimizing the risk of overlooking crucial details and contacts. Considering that CRM solutions can help shape and personalize your link-building and SEO parameters, it is a win-win scenario.
- Opportunities for inserting links — a high-end CRM solution is a great way to implement valuable data from third parties to your blog or other on-site pages without duplicate content and other issues. That reduces the overall stress and pressure, letting you skip writing articles from scratch every time you post something. CRM software automates the link-building process and assists in monitoring the way the target audience’s perception.
- Guest blogging — without a doubt, it is one of the easiest and most effective methods to generate and elevate your backlink profile. If you don’t want to lose track of prospective third parties to cooperate with, professional CRM solutions will help you fulfill guest blogging projects. It is a functional way to distinguish this effort from content syndication and prospective traffic cannibalism.
Final Thoughts
If you don’t want to face a sharp decline in your site’s ranks and a loss of organic traffic, taking care of duplicate content in advance is an excellent precautionary measure. This way, you will ensure your pages deliver only relevant and valid information while satisfying the needs of potential viewers and Google’s guidelines. Don’t hesitate to follow the recommendations described in this guide to guarantee your site’s steady performance.
This guest post have been gifted to Serpstat as a support to Ukraine people, economy and companies.
Цю гостьову публікацію було подаровано Serpstat, щоб висловити мою підтримку людям, економіці та компаніям України